TP最新版下载后,业务健康监控实战指南
下载好了TP最新版本,先别忙跑去开展业务如何在TP最新版下载中监控业务健康状况?, 要先投入几分钟把监控搭建起来。我一般会先开启TP的“健康检查”模块, 找到这个入口在系统设置的最底层位置。点击进入之后, 首先应该做的事情就是配置基础指标: CPU使用率、内存占用、磁盘I/O, 这三项是最基本的要求。我习惯将CPU阈值设定在80%, 若是一旦超出这个数值, TP就会自动发出告警。
硬件指标配置完毕后, 下一步需留意业务层面的数据 , TP的“事务追踪”功能极具实用性 , 其可记录每个请求的响应时间以及错误码 , 我会着重关注HTTP 500 和响应时间超出3秒的请求 , 这些常常是业务异常的早期信号 , 将这些信息对接至TP的仪表盘上 , 一眼便能看出哪个接口出现问题了 、。
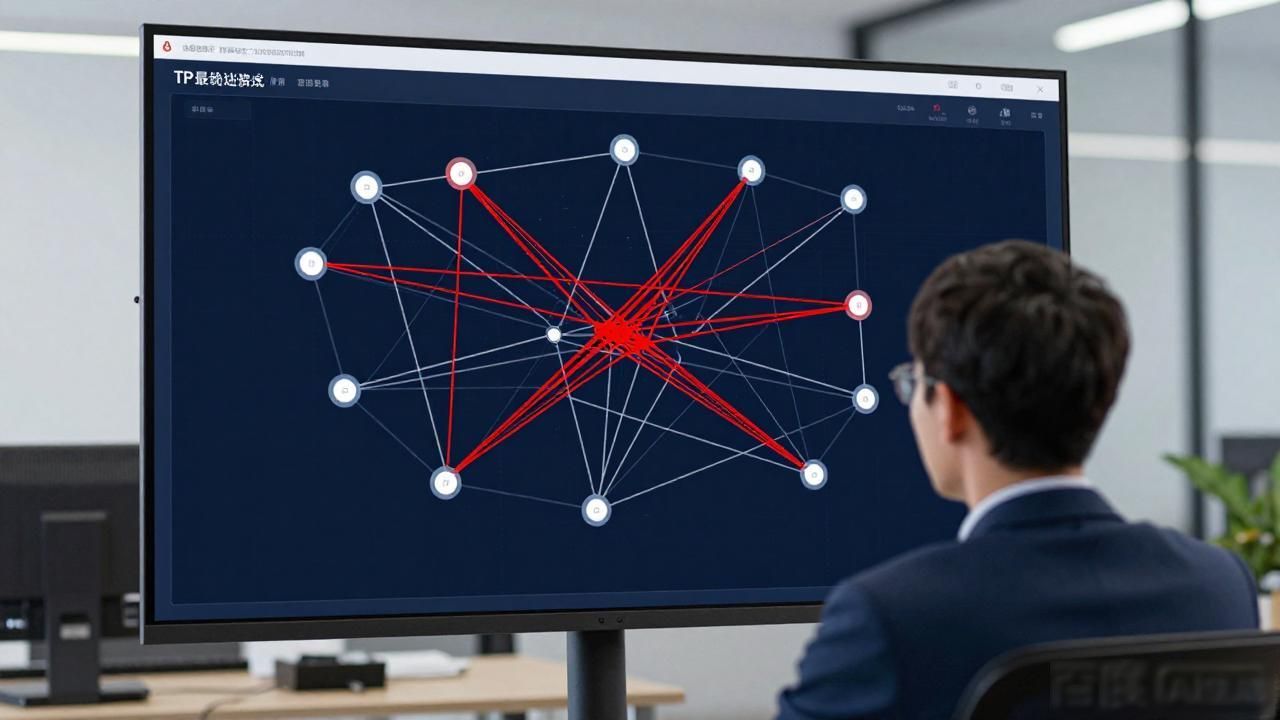
不要唯独去盯着数字, 可视化才是最为关键的。TP 最新推出的版本所自带的“实时拓扑图”, 能够自动去生成服务之间的调用关系。我每一次上线新的版本之时, 都会目不转睛地盯着这张图瞧, 如果某一个节点的连线突然间变粗或者变红, 那就表明流量出现异常状况或者性能瓶颈已然出现了。这样的一种视觉反馈, 比去看枯燥乏味的日志要快上十倍。
想要在隐患尚未显露之前就察觉到, 那就需要去设置具备合理性的告警方面的规则。我于TP之中进行了“滑动窗口”这一策略的配置: 要是在连续的5分钟时间范围以内, 错误率高于1%的情况出现, 那么便会借助钉钉以及邮件同时展开通知告知。要记住将告警划分等级, 属于紧急类型的才向全部成员发送, 普通程度的仅仅通知当日值班的班长。如此这般便不会致使团队被那些跟自身并不相干的消息所淹没, 导致应接不暇。
最后有个小技巧, TP名为“历史对比”的功能得充分加以利用。我会拿当前的数据去跟上周同一时间段的数据作一下对比, 要是响应时间忽然猛增50%, 就算绝对值没有超过阈值, 那也值得去进行排查。这样的趋势分析能够帮你找出那些逐步缓慢恶化的问题, 而并非一直等到系统崩溃了才匆忙去救火。